Bases de données relationnelles Hiver 2021
Geoffrey Glangine, M.Sc.
8TRD159Principes d'extraction des données dans une table
SQL ?
- Développé par IBM (1970)
- Le nouveau langage standard pour interagir avec les BDR
- SQL est maintenant une norme ISO
- Utilisé par la plupart des SGBD mais certaines petites différences peuvent exister
Modèle relationnel vs. SQL
Dû à l'historique des sgbdr, le langage SQL est très proche de l'algèbre et du modèle relationnel.
Lorsque le modèle relationnel parle de relations, d'attributs et de tuples,
SQL les appelle tables, colonnes et lignes.
En SQL il existe 2 types de mots :
- Mots réservés : partie fixe du langage ayant un sens précis. Doivent être écrits tels quels et ne peuvent être cassés sur plusieurs lignes.
- Mots utilisateur : représentent les noms d'objets comme les tables, les colonnes, etc.
Le langage SQL n'est pas sensible à la casse ! (sauf pour les comparaisons de chaînes de caractère évidement)
Un SGBD possède 2 langages, le langage de définition des données et le langage de manipulation
SQL permet de faire les 2 !
Cette capsule vidéo va présenter en détail le langage de manipulation des données.
Vous aurez besoin des 2 langages pour le projet final
Manipulation des données en SQL
Vous disposez de 4 opérations principales :
- INSERT : insertion des données
- SELECT : interrogation de la base de donnée
- UPDATE : mise à jour des données
- DELETE : suppression des données
Notons qu'on utilise des guillemets pour identifier les chaînes de caractères uniquement
On utilise donc pas de guillemets pour les booléens et les nombres
SELECT
D'après vous, quel est le résultat d'une requête SELECT ?
Composition de la reqête SELECT
La requête SELECT est généralement composée de 3 clauses :
- SELECT précise les valeurs qui constitue chaque lignes du résultat.
- FROM indique la ou les tables desquelles le résultat tire ses valeurs.
- WHERE indique la condition de sélection que doivent satisfaire les lignes de résultat.
Mais on peut la compléter de cette manière :
SELECT [DISTINCT|ALL]{*|expColonne [AS nom]] [,...]}
FROM nomTable [alias] [,...]
[WHERE condition]
[GROUP BY listeColonnes] [HAVING condition]
[ORDER BY listeColonnes]
L'ordre d'apparition des clauses SELECT FROM WHERE GROUP BY HAVING ORDER BY n'est pas interchangeable !
Par contre l'ordre de traitement des mots clés est différent de l'ordre d'écriture de la requète !
- FROM nom de la (des) table(s) à utiliser
- WHERE filtre les lignes selon une condition
- GROUP BY forme des groupes de lignes avec la même valeur pour une colonne
- HAVING filtre les groupes selon une condition
- SELECT choisit les colonnes
- ORDER BY spécifie l'ordre d'affichage
Comme le résultat de la requête SELECT est une table, il est temps de présenter les différents types de tables en SQL !
- Les tables de base : sont les tables que l'on utilise depuis le début. Elles sont stockées de manière permanente et sont accessibles par tous les utilisateurs de la base de données.
- Les résultats de requêtes SELECT : Ces tables sont volatiles, elles disparaissent après exécution de la requête.
- Les tables dérivées : Il est possible d'enregistrer le résultat d'une requête SELECT dans une table à l'aide d'une requête INSERT INTO
- Et les vues : Une vue est une table virtuelle dont le contenu est défini comme le résultat de la requête SELECT qui lui est attaché.
select NCLI, NOM, LOCALITE
from CLIENT;
| NCLI | NOM | LOCALITE | B062 | GOFFIN | Namur |
|---|---|---|
| B112 | HANSENNE | Poitiers |
| B332 | MONTI | Genève |
| ... | ... | ... |
select NCLI, NOM
from CLIENT
where LOCALITE = 'Toulouse';
| NCLI | NOM | B512 | GILLET |
|---|---|
| C003 | AVRON |
| D063 | MERCIER |
| ... | ... |
select distinct LOCALITE
from CLIENT
where CAT = 'C1';
Dans la clause WHERE, il est possible de mettre tous les opérateurs connus :
- égal à : =
- plus grand que : >
- plus petit que :<
- différent de : <>
- plus grand ou égal : >=
- plus petit ou égal : <=
Conditions plus complexes
Conditions plus complexes
in : pour indiquer un range de valeurs
select NCLI
from CLIENT
where CAT in ('C1','C2','C3');
Conditions plus complexes
not in : pour indiquer que ce que l'on recherche n'est pas dans un range de valeurs
select NCLI
from CLIENT
where CAT not in ('C1','C2','C3');
Conditions plus complexes
between : pour indiquer un range entre deux valeurs
select NCLI
from CLIENT
where COMPTE between 1000 and 4000;
Il est aussi possible de rechercher la présence de certains caractères dans un champ. La clause like permet de le faire
Categorie like '_1'
adresse like '%Neuve%'
- cette condition utilise un masque qui décrit la structure générale des données. Il faut utiliser le caractère "_" pour qu'il agisse comme un caractère quelconque.
- "%" est quand à lui une suite de caractère quelconques.
Les expressions composées
Comme dans tous les langages de programmation, il est possible d'utiliser les opérateurs d'algèbre de bool (and, or et not)
Exemple :
SELECT nom, adresse, compte
FROM Client
WHERE LOCALITE = 'Toulouse' and COMPTE > 0
Il est toujours possible d'utiliser des parenthèses pour spécifier explicitement les priorités des opérateurs
char_length(ch)
cast(v as t)
extract(u from d_t)
case when c1 then exp1
extract(year from datecreation) -1
Select NCLI,
case substring(CATEGORIE from 1 for 1)
when 'A' then 'BON'
when 'B' then 'MOYEN'
when 'C' then 'OCCASIONNEL'
else coalesce(CATEGORIE, 'INCONNU')
end, LOCALITE
from CLIENT;
- Il est toujours possible d'ordonner le résultat d'une requête SQL en utilisant la clause "order by NOM_COLONNE"
- Il est aussi possible de regrouper des données de la même manière avec la clause "group by NOM_COLONNE".
Les fonctions d'agrégation :
- COUNT() : Permet de compter toutes les lignes (compte aussi les doublons et les lignes nulles).
- AVG(nom_colonne) : donne la moyenne des valeurs d'une colonne
- SUM(nom_colonne) : donne la somme des valeurs d'une colonne
- MIN(nom_colonne) : donne la valeur minimum des valeurs d'une colonne
- MAX(nom_colonne) : donne la valeur maximum des valeurs d'une colonne
Bien entendu, les fonction d'agrégation retournent qu'une seule valeur, il est donc illégal de les utiliser en sélectionnant plusieurs lignes avec une fonction d'agrégation !
aussi elles ne peuvent être utilisés que dans la portion select ou having d'une requête
SELECT no_employé, count(salary)
FROM Employés;
Cette requête ne fonctionne pas !
SELECT count(*) FROM EmployésCette requête fonctionne !
Exemple complet avec les fonctions d'agrégation :
SELECT MIN(salary) AS myMin,
MAX(salary) AS myMay, AVG(salary) AS myAVG,
AVG(salary) AS myAVG
FROM Staff;
Utilisation de la clause GROUP BY
Il faut respecter certaines restriction pour regrouper les données :
Chaque item du SELECT doit retourner une seule valeur par groupe
La clause SELECT peut contenir seulement des noms de colonnes, des constantes et des fonctions d'agrégation.
Utilisation de la clause GROUP BY
Tous les noms de colonnes du SELECT doivent apparaître dans la clause GROUP BY, à monis que le nom ne soit utilisé seulement dans une fonction d'agrégation
Si WHERE est utilisé avec GROUP BY, WHERE est évalué d'abord, et ensuite les groupes sont formés avec les lignes restantes
Pour les besoins de GROUP BY, deux valeurs nulles sont considérées égales
La clause HAVING est toujours utilisée avec GROUP BY
Elle Sert à filtrer les groupes qui apparaissent dans la table finale, selon une condition
Elle fonctionne comme un WHERE sauf que WHERE filtre les lignes alors que HAVING filtre les groupes
Les noms des colonnes dans la portion HAVING doivent apparaître dans GROUP BY ou être contenus dans une fonction d'agrégation
Exemple
SELECT branchNo,
COUNT(staffNo) AS myCount,
SUM(salary) AS mySum
FROM Staff
GROUP BY branchNo
ORDER BY branchNo;
Compter le nombre de salariés par branche de l'entreprise et indiquer la somme de leur salaires
| BranchNo | Mycount | Mysum |
|---|---|---|
| B003 | 3 | 54000 |
| B005 | 2 | 39000 |
Pour chaque succursale avec plus d'un employé, trouver le nombre d'employés et leur salaire total (par succursale).
SELECT branchNo,
COUNT(staffNo) AS myCount,
SUM(salary) AS mySum
FROM Staff
GROUP BY branchNo
HAVING COUNT(staffNo) > 1;
ORDER BY branchNo;
| BranchNo | Mycount | Mysum |
|---|---|---|
| B003 | 3 | 54000 |
| B005 | 2 | 39000 |
Mot clé NULL
Dans notre requète il est possible de rechercher les colonnes ou Null est indiqué.
Select * FROM CLIENT
WHERE date_suppression IS NULL
attention il faut utiliser IS NULL et non date_suppression ‹› NULL
Les sous requêtes :
Il est toujours possible d'intégrer une requête SQL à l'intérieur d'une autre requête SQL.
SELECT NCLI
FROM CLIENT
WHERE LOCALITE='NAMUR'
Cette requête retourne (1,3,6,7)
SELECT NOM, DATE_COMMANDE
FROM COMMANDE
WHERE NCLI in (1,3,6,7)
Les sous requêtes :
Cela donne conc :
SELECT NOM, DATE_COMMANDE
FROM COMMANDE
WHERE NCLI in (SELECT NCLI
FROM CLIENT
WHERE LOCALITE='NAMUR');
Les jointures
La jointure permet de créer une table constituée des données de plusieurs tables :
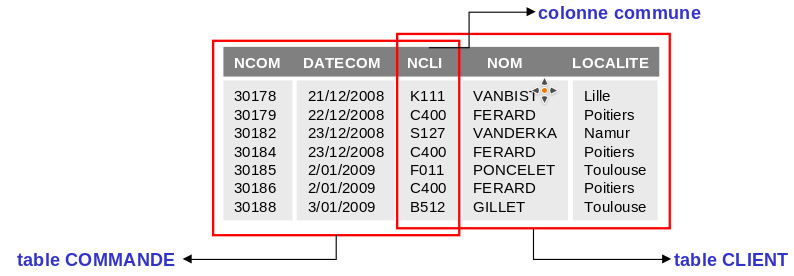
select NCOM, DATECOM, CLIENT.NCLI, NOM, LOCALITE
from COMMANDE, CLIENT
where COMMANDE.NCLI = CLIENT.NCLI;
Autres exemples (Jointure de 3 tables):
select CLIENT.NCLI, NOM, DATECOM, NPRO
from CLIENT, COMMANDE, DETAIL
where CLIENT.NCLI = COMMANDE.NCLI
and COMMANDE.NCOM = DETAIL.NCOM;
Autres exemples (Condition de jointure et conditions de sélection):
select NCOM, CLIENT.NCLI, DATECOM, NOM, ADRESSE
from COMMANDE, CLIENT
where COMMANDE.NCLI = CLIENT.NCLI
and CAT = 'C1'
and DATECOM < '23-12-2009';
Jointures ou sous requêtes ?
select NCOM,DATECOM
from COMMANDE
where NCLI in (select NCLI
from CLIENT
where LOCALITE = 'Poitiers');
=
select NCOM,
from COMMANDE,
where COMMANDE.NCLI = CLIENT.
and LOCALITE = 'Poitiers';
Cependant ce type de jointure a ses limites.
La sous-requête permet de formuler :
- une condition d'association (in)
- une condition de non-association (not in)
Alors que la jointure ne permet de formuler uniquement une condition d'association
Il est aussi possible de faire des jointures s'il n'y a pas de clé étrangères !
Interprétation du résultat d'une jointure.
Le résultat d'une jointure clé étrangère/Id représente les entités de la table de la clé étrangère
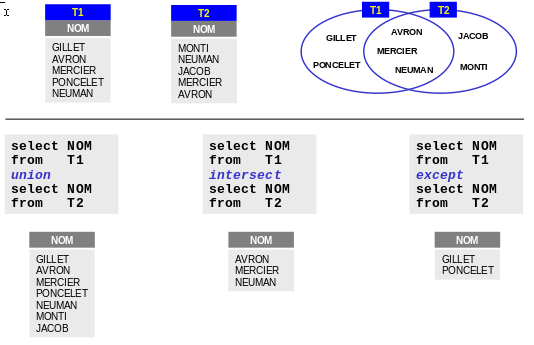
Opérateurs ensemblistes
Opérateurs ensemblistes :
Union, intersection, différence
Les jointures normalisées !
Les jointures effectuées directement dans la clause where étaient une méthode ancienne pour faire des jointures. Depuis la norme SQL 3, il faut utiliser le mot clé join pour effectuer les jointures. De plus celui ci permet une plus grande précision au niveau de la jointure. Les jointures normalisées s'expriment à l'aide du mot clef JOIN dans la clause FROM. Suivant la nature de la jointure, on devra préciser sur quels critères se base la jointure.
SELECT CLI_NOM, TEL_NUMERO
FROM CLIENT c
INNER JOIN TELEPHONE t
ON c.CLI_ID = t.CLI_ID
Le mot clef INNER est facultatif. Par défaut l'absence de précision de la nature de la jointure la fait s'exécuter en jointure interne.
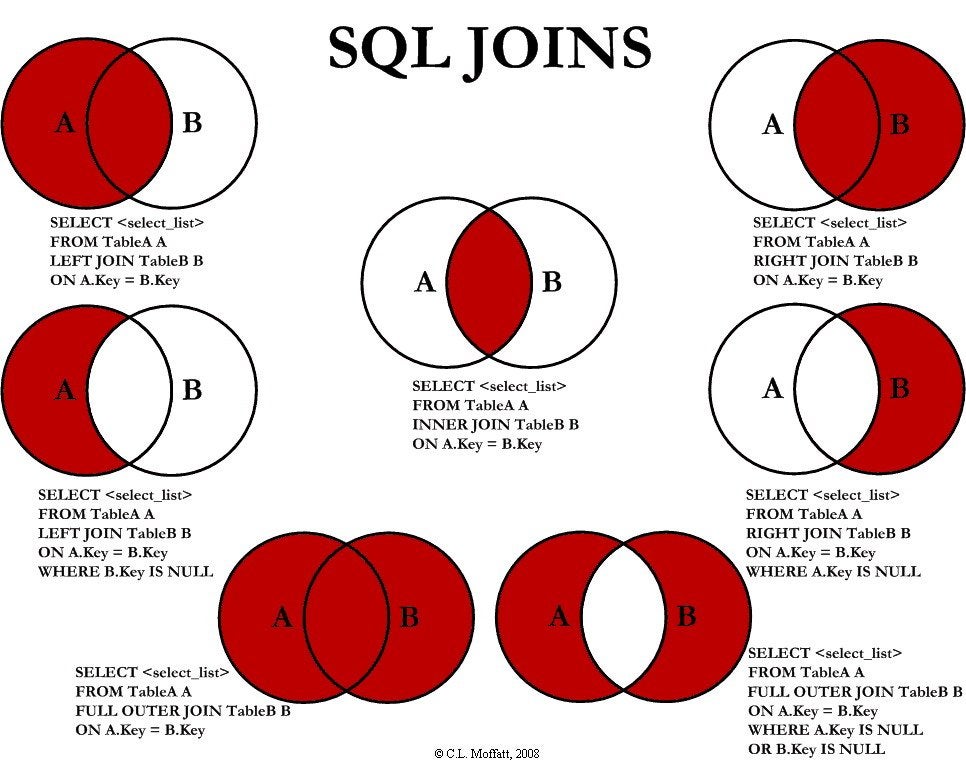
Les jointures externes
Il existe 3 types de jointures externes, les Left outer join, les right outer join et les full outer join.
SELECT colonnes
FROM TGauche LEFT OUTER JOIN TDroite ON condition de jointure
SELECT colonnes
FROM TGauche RIGHT OUTER JOIN TDroite ON condition de jointure
SELECT colonnes
FROM TGauche FULL OUTER JOIN TDroite ON condition de jointure
Les jointures externes
Les jointures externes sont extrêmement pratiques pour rapatrier le maximum d'informations disponible, même si des lignes de table ne sont pas renseignées entre les différentes tables jointes.
Les mots clefs LEFT, RIGHT et FULL indiquent la manière dont le moteur de requête doit effectuer la jointure externe. Il font référence à la table située à gauche (LEFT) du mot clef JOIN ou à la table située à droite (RIGHT) de ce même mot clef. Le mot FULL indique que la jointure externe est bilatérale.
Maintenant qu'on a vu l'usage du SELECT, il reste UPDATE, DELETE INSERT !
Modification des données dans une table
Pour ajouter une ligne dans la base de données, il suffit d'utiliser l'instruction insert into :
INSERT INTO client values(1,'Marie', 'Tremblay');
Si la table contient déjà des lignes qui violent la contrainte que l'on souhaite ajouter, alors il sera impossible de l'ajouter.
Modification des données dans une table
Il est possible de spécifier les colonnes que l'on veut remplir :
INSERT INTO client (prenom_client, nom_client) values('Marie', 'Tremblay');
Si la table contient déjà des lignes qui violent la contrainte que l'on souhaite ajouter, alors il sera impossible de l'ajouter.
Ajout des données dans une table
Il est possible de spécifier les colonnes que l'on veut remplir :
INSERT INTO client (prenom_client, nom_client)
values('Marie', 'Tremblay'),
('Serge', 'Gagnon');
L'argument de la fonction insert into est une table statique, il est donc possible d'ajouter plusieurs lignes à la fois !
Suppression des données dans une table
Il est possible de supprimer des lignes dans une table:
DELETE FROM client WHERE id_client='1';
Nous verrons l'instruction where dans le prochain cours !
Modification des lignes dans une table
Il est possible de modifier des lignes dans une table:
UPDATE client
SET nom_client='Vivaldi'
WHERE id_client='1';
Erreurs fréquentes
Il est important de noter que la mise à jour, et la modification des données ne sera effectuée uniquement si les résultats obtenus respectent toutes les contraintes définies par votre schéma de base de données !